פרק 3 צעדים ראשונים
- בקורס נשתמש בתוכנת RStudio
התצוגה מחולקת ל4 חלקים שמציגים דברים שונים.
מצורף קישור שמכיל לא מעט “טריקים” וקיצורי מקלדת לתוכנה עצמה.
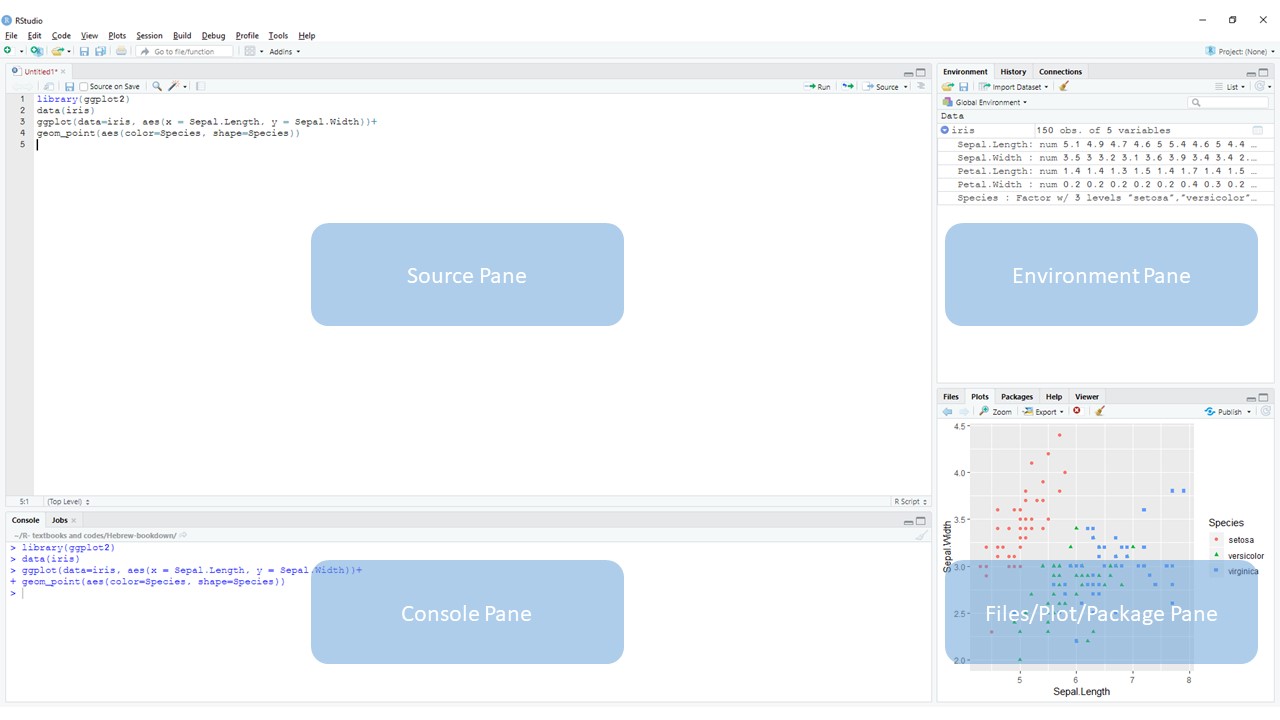
תרשים 3.1: תצוגת Rstudio
3.1 עזרה
כדי לבדוק את המסמכים שמסבירים על פקודה מסוימת ניתן להשתמש בחלונית העזרה ולבצע בה חיפוש,
או לרשום ב Console ? ואת שם הפקודה.
למשל lm ? יפתח את חלון העזרה לפקודה שמבצעת אמידה לרגרסיה לינארית.
הדבר שקול לשימוש בפקודה הבאה
help(lm)
3.2 פקודות
ניתן לכתוב פקודה בקונסול, או לכתוב אותה בחלון הטקסט ולהריץ אותה דרך לחיצה על
Shift+Enter או כפתור run.
שימוש בעורך הטקסט לכתיבת קוד היא דרך טובה לוודא שאתם מריצים את אותו הקוד בכל פעם.
בנוסף, היא מאפשרת לכם לשתף עם אנשים אחרים את הקוד שכתבתם.
שמירת משתנה בזכרון (global enviroment) מתבצעת ע”י שימוש באופרטור <-, לחילופין, ניתן להשתמש גם באופרטור =, אבל ב-R זה נחשב ל”סטייל רע”
בכל מקרה, יש להבדיל בין האופרטור = שמקצה אוביקט לזכרון לבין == שהוא אופרטור לוגי שבוחן האם שני צדי המשואה שווים ומחזיר ערך TRUE או FALSE
3.3 פעולות חישוב פשוטות
ניתן להשתמש ב-R לביצוע פעולות חישוב פשוטות, נראה זאת דרך הדוגמאות הבאות:
2+2 # שתיים ועוד שתיים## [1] 42^3 # שתיים בחזקת שלוש## [1] 8log(1) # לוג אחת## [1] 0abs(-2) # ערך מוחלט של מינוס שתיים## [1] 2floor(3.2) # לעגל את המספר 3.2 כלפי מעטה## [1] 3ceiling(3.2) # לעגל את המספר 3.2 כלפי מעלה## [1] 47%%3 # השארית שמתקבלת מחלוקה של 7 בשלוש ## [1] 17%/%3 # ?כמה פעמים 3 נכנס בשבע## [1] 2floor(7/3) # ?כמה פעמים 3 נכנס בשבע## [1] 23.3.1 תנאים לוגים
1<2 # ?האם אחת קטן משתיים## [1] TRUE1==2 # ?האם אחת שווה לשתיים## [1] FALSE1>=2 # ?האם אחת גדול או שווה לשתיים## [1] FALSE1!=2 # ?אם אחת שונה משתיים## [1] TRUE3.3.2 מספר תנאים לוגים
האופרטור | מציין או, והאופרטור & מציין וגם
(1<2) & (3==4) # ?אחת קטן משניים וגם שלוש שווה לארבע## [1] FALSE(1<2) | (3==4) # ?אחת קטן משניים או שלוש שווה לארבע## [1] TRUE3.4 סוגי אובייקטים
קיימים סוגים רבים של אובייקטים, כעת נזכיר כמה מהחשובים שבהם.
3.4.1 ווקטורים (Vectors)
סדרה של ערכים שמסודרת בטור/ שורה
הערכים יכולים להיות מסוגים (class) שונים.
ניתן ליצור ווקטור ע”י שימוש בפקודה c
למשל
c(1,2,3)## [1] 1 2 3c("John","David","Sarah")## [1] "John" "David" "Sarah"ניתן להשתמש באופרטור : או בפקודת seq
כדי לייצר ווקטור בצורה מעט יותר פשוטה מבלי לציין את כל הערכים בו
1:10## [1] 1 2 3 4 5 6 7 8 9 10seq(from=1, to=10)## [1] 1 2 3 4 5 6 7 8 9 10seq(from=1, to=10,by=2)## [1] 1 3 5 7 9rep(x = 1:2,times=5)## [1] 1 2 1 2 1 2 1 2 1 2rep(x = 1:2,each=5)## [1] 1 1 1 1 1 2 2 2 2 23.4.1.1 פעולות חישוב בווקטורים
ניתן לבצע פעולות חישוב ותנאים לוגים גם על וקטורים
x<-1:10
mean(x) #הממוצע של X## [1] 5.5min(x) #הערך המינימלי של X## [1] 1max(x) #הערך המקסימלי של X## [1] 10median(x) #החציון של X## [1] 5.5length(x) #האורך של X## [1] 10y<-11:20
x+y## [1] 12 14 16 18 20 22 24 26 28 30x*y## [1] 11 24 39 56 75 96 119 144 171 200x%*%y## [,1]
## [1,] 935x>5## [1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUEניתן לבחור ערכים מתוך ווקטור במספר דרכים
x[c(1,2)] #choose the first two values in X## [1] 1 2x[-1] #choose all but the first value in X## [1] 2 3 4 5 6 7 8 9 10x[x<5] # choose all the values smaller than 5## [1] 1 2 3 4x[x %in% c(1, 2, 5)] #choose values in the set 1,2,5## [1] 1 2 5ווקטורים נחלקים למס’ סוגים (atomic types)-
logical- מקבלת את הערךTRUEאוFALSEinteger- מקבל מספרים שלמים מספרים אלו ייוצגו עם האות L כ-5Lnumeric- מספרים ריאליים (שאינם מורכבים)complex- עבור מספרים מורכביםcharacter- נקרא לעיתים גם “strings” מתייחס לערך כאל טקסט
סוג הווקטור יהיה המכנה המשותף הנמוך של כל הערכים בווקטור. למשל:
a1<-c(TRUE,FALSE)
a1 ## [1] TRUE FALSEclass(a1)## [1] "logical"a2<-c(a1,3)
a2## [1] 1 0 3class(a2)## [1] "numeric"a3<-c(a2,1+2i)
a3## [1] 1+0i 0+0i 3+0i 1+2iclass(a3)## [1] "complex"a4<-c(a3,"David")
a4## [1] "1+0i" "0+0i" "3+0i" "1+2i" "David"class(a4)## [1] "character"3.4.2 מטריצות (Matrices)
מטריצה היא ווקטור שנפרס למס’ עמודות/שורות, או אסופה של מס’ ווקטורי שורה או ווקטורי עמודה
יצירת מטריצה מווקטור נתון:
matrix(1:4,nrow = 2 ) # ברירת המחדל היא לפרוס את הווקטור לפי עמודות## [,1] [,2]
## [1,] 1 3
## [2,] 2 4matrix(1:4,nrow = 2,byrow = TRUE ) # פורס את הווקטור לפי שורות## [,1] [,2]
## [1,] 1 2
## [2,] 3 4על מנת לחבר מס’ ווקטורים למטריצה נשתמש בפקודות cbind או rbind
a<-1:3
b<-letters[1:3]
cbind(a,b)## a b
## [1,] "1" "a"
## [2,] "2" "b"
## [3,] "3" "c"a<-1:3
b<-letters[1:3]
x<-rbind(a,b)
x## [,1] [,2] [,3]
## a "1" "2" "3"
## b "a" "b" "c"נשים לב שבעוד שהקלאס של ווקטור 1 הוא נומרי, הקלאס של העמודה שמייצגת אותו במטריצה הוא character, לפי כלל המכנה המשותף הנמוך.
class(a)## [1] "integer"class(x[1,])## [1] "character"כיוון שמטריצה זו היא בעצם פריסה של הווקטור
c(a,b)
3.4.2.1 פעולות על מטריצות
- מציאת מימדי המטריצה ניתנת על-ידי שימוש בפקודה
dim
y<-matrix(c(1:4),2)
dim(y)## [1] 2 2- מציאת האלכסון הראשי של מטריצה ניתנת על-ידי הפונקציה
diag
diag(y)## [1] 1 4- שחלוף מטריצה (transpose) מתבצע ע”י הפקודה
t
t(y)## [,1] [,2]
## [1,] 1 2
## [2,] 3 4- מציאת הפונקציה ההופכית ניתנת ע”י הפקודה
solve
solve(y)## [,1] [,2]
## [1,] -2 1.5
## [2,] 1 -0.5- מציאת הדטרמיננטה של מטריצה ניתנת על-ידי הפונקציה
det
det(y)## [1] -23.4.2.2 פעולות חישוב במטריצות
ככלל פעולות במטריצות נעשות על כל איבר בנפרד
y<-matrix(1:4,nrow = 2)
y1<-matrix(5:8,nrow = 2)
y## [,1] [,2]
## [1,] 1 3
## [2,] 2 4y*2+1## [,1] [,2]
## [1,] 3 7
## [2,] 5 9כפל מטריצות
כפל של מטריצות מבוצע ע”י שימוש באופרטור %*%

תרשים 3.2: כפל מטריצות, מקור:ויקיפדיה
y ; y1 ; y%*%y1## [,1] [,2]
## [1,] 1 3
## [2,] 2 4## [,1] [,2]
## [1,] 5 7
## [2,] 6 8## [,1] [,2]
## [1,] 23 31
## [2,] 34 46לחילופין, לעיתים נדרש לכפל של האיבר ה [i,j] ממטריצה אחת באיבר ה [i,j] במטריצה שנייה מבצעים פעולה שנקראת
Element-wise multiplication והיא מבוצעת תוך שימוש באופרטור *
y ; y1 ; y*y1## [,1] [,2]
## [1,] 1 3
## [2,] 2 4## [,1] [,2]
## [1,] 5 7
## [2,] 6 8## [,1] [,2]
## [1,] 5 21
## [2,] 12 323.4.3 מסגרת נתונים (Data.frame)
מסגרת נתונים היא טבלה דו-מימדית בה כל עמודה מכילה ערכים של משתנה מסויים. וכל שורה מכילה ערך אחד מכל אחד מהמשתנים. בשונה ממטריצה, במסגרת נתונים כל עמודה יכולה לקבל קלאס אחר. כל אחת מהעמודות שבמסגרת הנתונים היא ווקטור, ולכן ניתן לבצע עליה את הפעולות שניתן לבע על ווקטורים
df<-data.frame(id = 1:100,
height = rnorm(n = 100,mean = 175,sd = 2),
weight = rnorm(n = 100, mean = 70, sd=5),
gender = sample(x= c("man","woman"),size = 100,replace = TRUE,prob = c(0.6,0.4)))נתחיל לבחון את הדאטה
summary(df)## id height weight gender
## Min. : 1.00 Min. :169.9 Min. :55.99 Length:100
## 1st Qu.: 25.75 1st Qu.:173.4 1st Qu.:67.15 Class :character
## Median : 50.50 Median :174.7 Median :71.26 Mode :character
## Mean : 50.50 Mean :174.9 Mean :70.32
## 3rd Qu.: 75.25 3rd Qu.:176.3 3rd Qu.:74.06
## Max. :100.00 Max. :179.6 Max. :83.13נסתכל על התצפיות הראשונות והאחרונות בדאטה
head(df)## id height weight gender
## 1 1 175.3349 71.56548 woman
## 2 2 174.8281 71.40605 woman
## 3 3 176.4068 78.96905 woman
## 4 4 176.4062 73.83633 man
## 5 5 172.7897 55.98755 man
## 6 6 173.6475 75.90108 womantail(df,n = 3)## id height weight gender
## 98 98 178.7915 68.84001 man
## 99 99 177.9052 75.01837 woman
## 100 100 177.5785 60.99108 manנבדוק מהם שמות העמודות
names(df)## [1] "id" "height" "weight" "gender"עוד דרך נחמדה להסתכל על הדאטה היא שימוש בפקודה str
str(df)## 'data.frame': 100 obs. of 4 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ height: num 175 175 176 176 173 ...
## $ weight: num 71.6 71.4 79 73.8 56 ...
## $ gender: chr "woman" "woman" "woman" "man" ...נמצא את מס’ העמודות, מס’ השורות או המימדים של מסגרת הנתונים
dim(df)## [1] 100 4nrow(df)## [1] 100ncol(df)## [1] 4ניצור מסגרת חדשה שמכילה רק את הגברים
men.df<-subset(df,subset = df$gender=="man")
men.df1<-df[which(df$gender=="man"),]
all.equal(men.df,men.df1)## [1] TRUEניתן לגשת לשורה ספציפית ע”י שימוש בסוגריים המרובעים
men.df[2,]## id height weight gender
## 5 5 172.7897 55.98755 manניתן להגדיר את המשתנה gender בתור משתנה קטגוריאלי
df$gender<-as.factor(df$gender)
levels(df$gender)## [1] "man" "woman"כדי לבחור משתנה אחד מתוך הדאטה משתמשים באופרטור $
ניצור משתנה (עמודה) בדאטה df על-ידי df$age
df$age<-rnorm(100,25)על טבלאות נתונים data.table ארחיב בפרק (4.2)
3.4.4 רשימות lists
רשימות הן “סל קניות” של מס’ אובייקטים (לאו דווקא מאותו הסוג)
נגדיר רשימה שמכילה מסגרת נתונים מטריצה ווקטור
my_list<-list(char= "Ella",
mat= matrix(1:10,nrow = 2),
1:5) # לא חייבים להגדיר שם לכל אלמנט ברשימה
my_list## $char
## [1] "Ella"
##
## $mat
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 3 5 7 9
## [2,] 2 4 6 8 10
##
## [[3]]
## [1] 1 2 3 4 5ניתן לשלוף אלמנט של הרשימה כרשימה ע”י שימוש בסוגרים מרובעים []
my_list["char"]## $char
## [1] "Ella"class(my_list["char"])## [1] "list"ניתן גם לבחור את האלמנט ולשמור על הסוג שלו תוך שימוש בסוגריים מרובעים כפולים
my_list[["char"]]## [1] "Ella"class(my_list[["char"]])## [1] "character"3.5 פונקציות
ב-R אפשר להגדיר פונקציות בהגדרה אישית , כעת נדגים כיצד מגדירים פוקנציה חדשה.
מבנה הפונקציה הוא קבוע ומופיע מטה. אנחנו צריכים לבחור את שם הפונקציה ואת הארגומנטים שנרצה שהיא תקבל. בתוך הסוגריים המסולסלים נגדיר את דרך הפעולה של הפונקציה,הערך שהפונקציה תחזיר יהיה הערך שמפיע בתוך פקודת ה return(). אם לא קראנו לפקודת return באופן מפורשת הערך האחרון שיודפס בפונקציה יהיה הערך שהיא תחזיר.
name <- function(variables) {
}נגדיר פונקציה שבודקת האם מספר הוא זוגי
is.even <- function(num) {
return(num%%2==0)
}נבחן את הפונקציה שלנו
x<-(1:10)
is.even(num=x)## [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUEis.even(-2)## [1] TRUEis.even(3)## [1] FALSEis.even(3.5)## [1] FALSEניתן להגדיר גם פונקציות עם ארגומנט שיקבלו ערכי ברירת מחדל, אלו ערכים שייבחרו כל עוד לא נציין אחרת. למשל, נגדיר פונקציה טיפשית שמייצרת ממוצע בין שני מספרים. בנוסף, אם אחד המספרים לא הוגדר מראש נשתמש במספר 10
my_mean<-function(x,y=10) {
return(mean(c(x,y)))
}
my_mean(x=5)## [1] 7.5my_mean(x=5,y=7)## [1] 63.6 לולאות
3.6.1 לולאת for
אם אנחנו רוצים לבצע את אותה פעולה הרבה פעמים, אנחנו יכולים להשתמש בלולאה לשם כך נגדיר את הלולאה לפי המבנה הבא
for (variable in vector) {
}כמה נרות צריך בחג החנוכה בסך הכל?
x<-1:8
total_candles<-0 #מספר הנרות הראשוני
for (i in x) {
i_candles<-i+1 #מספר הנרות ביום ה-i
total_candles<-total_candles+i_candles
print(i_candles) # נדפיס את מספר הנרות שאנחנו נדרשים אליהם בכל יום
}## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6
## [1] 7
## [1] 8
## [1] 9total_candles # מספר הנרות הכולל לכל החג## [1] 443.6.2 לולאת while
ניתן לבצע לולאה כל עוד תנאי כלשהו מתקיים, אנחנו משתמשים בלולאה הזו פחות, אבל לפעמים זה שימושי, אבצע את הלולאה הקודמת תוך שימוש בלולאת while
total_candles<-0 #מספר הנרות הראשוני
n=1
while (n<=8) {
i_candles<-n+1 #מספר הנרות ביום ה-i
total_candles<-total_candles+i_candles
print(n) # נדפיס את היום שבו אנחנו נמצאים כדי לראות שהלולאה נעצרת לאחר שמונה ימים
n<-n+1
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6
## [1] 7
## [1] 8total_candles # מספר הנרות הכולל לכל החג## [1] 443.6.3 לולאת apply
apply היא לולאה שעובדת על מערכים- (מערך דו מימדי הוא מטריצה) לולאה זו מחשבת פונקציה על כל שורה או עמודה של המערך
היא מוגדרת כדלהלן: apply(X, MARGIN, FUN, ...)
כאשר
X היא המטריצה
כאשר MARGIN==1 הפונקציה מבוצעת על שורות, ו2 עבור עמודות.
FUN מציין את הפוקציה שרוצים לבחור
ניקח דאטה שמגיע בתוך הR ונחשב עבורו ממוצע לכל עמודה
apply(mtcars,2,mean)## mpg cyl disp hp drat wt
## 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250
## qsec vs am gear carb
## 17.848750 0.437500 0.406250 3.687500 2.8125003.6.4 לולאת lapply
ביצוע apply על רשימה או ווקטור
הפקודה תחזיר רשימה שכל אחד מהאלמנטים שלה מכיל את התוצאה של הפונקציה לאלמנט ברשימה הראשונית
ניצור רשימה שמכילה מס’ מטריצות ומסגרות נתונים ונחשב את המימדים של כל אחד מהאלמנטים שבתוך הרשימה
my_list<-list(mtcars,
matrix(1:10,nrow = 2))
lapply(my_list,dim)## [[1]]
## [1] 32 11
##
## [[2]]
## [1] 2 5למתקדמים, אנחנו יכולים להכניס פונקציית apply בתוך פונקציית הlapply
למשל, נחשב את הממוצע של כל עמודה לכל אחד מהאלמנטים ברשימה שלנו.
נרצה לראות שהממוצע של כל עמודה זהה לממוצע שחישבנו בapply
lapply(my_list,function(x) apply(x, 2, mean))## [[1]]
## mpg cyl disp hp drat wt
## 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250
## qsec vs am gear carb
## 17.848750 0.437500 0.406250 3.687500 2.812500
##
## [[2]]
## [1] 1.5 3.5 5.5 7.5 9.53.6.5 לולאת sapply
כיוון שלא תמיד נוח לעבוד עם רשימות, לולאת sapply מחזירה אפשרות נוחה יותר לתוצאת הlapply
למעשה נקבל תוצאה זהה לתוצאת הlaplly אם נבחר ב
simplify=FALSE
sapply(my_list,dim)## [,1] [,2]
## [1,] 32 2
## [2,] 11 5sapply(my_list,dim,simplify = FALSE)## [[1]]
## [1] 32 11
##
## [[2]]
## [1] 2 5