פרק 4 סידור הנתונים
פרק זה יעסוק בסידור וניקיון הנתונים
4.1 טעינה ושמירת בסיסי נתונים
library(foreign) # Read Data Stored by 'Minitab', 'S', 'SAS', 'SPSS', 'Stata' 5-12 etc.
library(readstata13) # Read Data Stored by stata13
library(haven) # Read Data Stored by stata14+
library(data.table) # Reads csv, tsv files## data.table 1.14.2 using 4 threads (see ?getDTthreads). Latest news: r-datatable.comlibrary(readxl) # Reads xls,xlsx files
library(writexl) # Writes xls,xlsx filesdf<-airquality
write_xlsx(x = df, path ="./filename1.xlsx") #export to xlsx
fwrite(x = df, file ="./filename1.csv") #export to csv
save(df,file ="./filename1.Rda")
rm(df)xlsxfile<-read_xlsx(path ="./filename1.xlsx",sheet = 1) #import the xlsx
csvfile<-fread(file ="./filename1.csv" ) #import the csv
load(file ="./filename1.Rda") #import the Rda
rm(xlsxfile,csvfile)4.1.1 יתרונות וחסרונות לכל שיטה
4.2 טבלאות נתונים
data.table היא הרחבה לאובייקט מסוג data.frame.
מרבית הפעולות שנעשה על הדאטה ייראו כך
DT[i, j, by]
כאשר נבחר שורות i
עמודות j
לפי קבוצה by
4.2.1 יצירת טבלת נתונים
כדי להתחיל לעבוד עם טבלת נתונים יש להגדיר אותה ככזו תחילה. ניתן לעשות זאת ע”י יצירת טבלת נתונים כך-
data.table(x=rnorm(5,mean=0,sd=1), y=seq(1,5), z=sample(letters,5,replace = TRUE))## x y z
## 1: 0.5643942 1 e
## 2: 0.3013421 2 r
## 3: -0.9449019 3 a
## 4: 0.2653043 4 s
## 5: -2.1475213 5 uע”י המרת data frame לטבלת נתונים data table
class(df)## [1] "data.frame"dt<-as.data.table(df)
class(dt)## [1] "data.table" "data.frame"או ע”י קריאת קובץ
csv
עם פקודת
fread
.
4.2.2 פעולות על בסיס הנתונים
אנחנו מבצעים פעולות על אובייקטים מסוג data.table.
טבלת הנתונים מצמצמת את הדאטה על בסיס איזשהו תנאי עבור השורות, לאחר מכן מבצעת איזושהי פעולה מתמטית בעמודות,
בתת הקבוצה שיוגדר ע”י
by
נתחיל מלהסתכל על שלוש השורות הראשונות בדאטה
dt[1:3,]## Ozone Solar.R Wind Temp Month Day
## 1: 41 190 7.4 67 5 1
## 2: 36 118 8.0 72 5 2
## 3: 12 149 12.6 74 5 3אם נרצה למצוא את הממוצע החודשי של עוצמת הרוח נשתמש בפקודה הבאה:
dt[,mean(Wind),by="Month"] ## Month V1
## 1: 5 11.622581
## 2: 6 10.266667
## 3: 7 8.941935
## 4: 8 8.793548
## 5: 9 10.180000למעשה יצרנו
data.table
חדש, שמכיל רשימה של החודשים עם ממוצע עוצמת הרוח, כל המשתנים האחרים לא יופיעו בטבלת הנתונים החדשה.
כמו כן, לא הגדרנו את שם העמודה שתכיל את הממוצע ולכן היא תוגדר להיות
V1.
בדוגמה הבאה ארצה להציג גם את הממוצע וגם את הערך המקסימלי של עוצמת הרוח לפי היום בשבוע,
לצורך כך צריך למצוא את התאריך של כל תצפית, ואז באמצעות פקודת ה
weekdays
נתן לכל תאריך את היום בשבוע המאתים לו.
הוספת משתנה חדש לתאריך
# Making a valid date
dt$date<-as.Date(paste("1973",dt$Month,dt$Day,sep = "-"))
# Adding weekdays to each date
dt$weekday<-as.factor(weekdays(dt$date))
# rearranging the weekdays Sunday to Saturday
dt$weekday <-factor(dt$weekday, levels= c("Sunday", "Monday",
"Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"))
# calculating the mean by week*monthnewdt<-dt[,
list(group_mean=mean(Solar.R,na.rm = TRUE),
group_max=max(Solar.R,na.rm = TRUE)),
by=c("weekday","Month")]
head(newdt[order(Month,weekday)],10) # order first by weekday then by months## weekday Month group_mean group_max
## 1: Sunday 5 167.0000 290
## 2: Monday 5 148.5000 299
## 3: Tuesday 5 185.2000 320
## 4: Wednesday 5 143.8000 334
## 5: Thursday 5 204.2000 307
## 6: Friday 5 152.3333 313
## 7: Saturday 5 281.3333 322
## 8: Sunday 6 274.7500 323
## 9: Monday 6 154.2500 259
## 10: Tuesday 6 179.2500 2504.2.3 צמצום בסיס הנתונים בהתבסס על תנאי
נסקור מספר דרכים למצצם את בסיס הנתונים, שיטת אלו יעבדו גם על צמצום ווקטורים
4.2.3.1 שימוש בתנאי מתמטי
highmonths<-dt[Month>7,]4.2.3.2 שימוש בווקטור שמכיל מידע על מה לשמור נרצה לשמור
months.to.keep<-c(5,7,9)
evenmonths<-dt[Month %in% months.to.keep,]4.2.3.3 לשמור רק שורות שמכילות איזשהו טקסט
בדוגמה הבאה אצור משתנה חדש בשם type ואכניס לכל טבלת הנתונים שלושה ערכים עבורו.
בשלב הבא, אצור טבלת נתונים חדשה שמכילה רק שורות שבהם ה- type אינו מכיל את הביטוי B
dt$type<-rep(c("AB","B","A","C","b"),len=nrow(dt))
keep.r<-!grepl("^B", dt$type)
No.letter.B<-dt[keep.r,]
head(No.letter.B)## Ozone Solar.R Wind Temp Month Day date weekday type
## 1: 41 190 7.4 67 5 1 1973-05-01 Tuesday AB
## 2: 12 149 12.6 74 5 3 1973-05-03 Thursday A
## 3: 18 313 11.5 62 5 4 1973-05-04 Friday C
## 4: NA NA 14.3 56 5 5 1973-05-05 Saturday b
## 5: 28 NA 14.9 66 5 6 1973-05-06 Sunday AB
## 6: 19 99 13.8 59 5 8 1973-05-08 Tuesday A4.2.4 אופרטורים מיוחדים לטבלאות נתונים
- האופרטור
N.סופר את מספר התצפיות. =:נועד על מנת ליצור משתנה חדש לפי התנאים על השורות כל שורה שאינה מקיימת את התנאי תקבלNASD.דרך נוחה לבצע פעולות על העמודות (משתנים),אם נרצה לבחור רק בחלקם נגדיר זאת ע”יSDcols.
dt<-dt[,-c("weekday","type"),]
head(dt)## Ozone Solar.R Wind Temp Month Day date
## 1: 41 190 7.4 67 5 1 1973-05-01
## 2: 36 118 8.0 72 5 2 1973-05-02
## 3: 12 149 12.6 74 5 3 1973-05-03
## 4: 18 313 11.5 62 5 4 1973-05-04
## 5: NA NA 14.3 56 5 5 1973-05-05
## 6: 28 NA 14.9 66 5 6 1973-05-06dt[, .N, by=Month] # Count obs per Month## Month N
## 1: 5 31
## 2: 6 30
## 3: 7 31
## 4: 8 31
## 5: 9 30נבדוק באילו ימים הייתה רוח גבוה מעוצמת הרוח החציונית
dt[Wind>median(Wind),highwind := TRUE]
dt## Ozone Solar.R Wind Temp Month Day date highwind
## 1: 41 190 7.4 67 5 1 1973-05-01 NA
## 2: 36 118 8.0 72 5 2 1973-05-02 NA
## 3: 12 149 12.6 74 5 3 1973-05-03 TRUE
## 4: 18 313 11.5 62 5 4 1973-05-04 TRUE
## 5: NA NA 14.3 56 5 5 1973-05-05 TRUE
## ---
## 149: 30 193 6.9 70 9 26 1973-09-26 NA
## 150: NA 145 13.2 77 9 27 1973-09-27 TRUE
## 151: 14 191 14.3 75 9 28 1973-09-28 TRUE
## 152: 18 131 8.0 76 9 29 1973-09-29 NA
## 153: 20 223 11.5 68 9 30 1973-09-30 TRUEנחשב ממוצע לכל עמודה
dt[ , lapply(.SD, mean), by = Month]## Month Ozone Solar.R Wind Temp Day date highwind
## 1: 5 NA NA 11.622581 65.54839 16.0 1973-05-16 NA
## 2: 6 NA 190.1667 10.266667 79.10000 15.5 1973-06-15 NA
## 3: 7 NA 216.4839 8.941935 83.90323 16.0 1973-07-16 NA
## 4: 8 NA NA 8.793548 83.96774 16.0 1973-08-16 NA
## 5: 9 NA 167.4333 10.180000 76.90000 15.5 1973-09-15 NAנשים לב שקיבלנו NA, זה קורה משום R מחשב ממוצע לסדרת ערכים שמורכבת גם מתצפיות חסרות.
בשלב הבא אבצע את הממוצע רק על חלק מהעמודות ואציין במפורש שחישוב הממוצע יתעלם מNA
include<-c("Ozone","Solar.R","Wind","Temp")
dt[order(Month), lapply(.SD, mean,na.rm=TRUE), by = Month, .SDcols = include]## Month Ozone Solar.R Wind Temp
## 1: 5 23.61538 181.2963 11.622581 65.54839
## 2: 6 29.44444 190.1667 10.266667 79.10000
## 3: 7 59.11538 216.4839 8.941935 83.90323
## 4: 8 59.96154 171.8571 8.793548 83.96774
## 5: 9 31.44828 167.4333 10.180000 76.900004.2.4.1 זהירות עם הוספת עמודות חדשות
מילה של זהירות לגבי יצירת משתנים חדשים.
אם אנחנו יוצרים טבלת נתונים על ידי dt.new<-dt.old
ואז בטבלה החדשה יוצרים משתנה חדש ע”י שימוש באופרטור
=:
העמודה החדשה תתווסף לשתי טבלאות הנתונים.
הסיבה היא שטבלאות הנתונים לא באמת מכפילות את עצמן על מנת לחסוך בזכרון.
אם ערכנו אי-אלו שינויים כך שהן לא זהות הוספת המשתנה תופיע רק בטבלה שסימנו.
DT <- data.table(x=rnorm(10,mean=0,sd=1), y=seq(1,10), z=sample(letters,10,replace = TRUE))
dt<-DT
dt[x<3,k:=TRUE]
head(dt)## x y z k
## 1: 0.72475923 1 h TRUE
## 2: -0.01507926 2 c TRUE
## 3: 3.61655899 3 r NA
## 4: 0.85979235 4 t TRUE
## 5: -0.24817513 5 n TRUE
## 6: 0.61014299 6 v TRUEhead(DT)## x y z k
## 1: 0.72475923 1 h TRUE
## 2: -0.01507926 2 c TRUE
## 3: 3.61655899 3 r NA
## 4: 0.85979235 4 t TRUE
## 5: -0.24817513 5 n TRUE
## 6: 0.61014299 6 v TRUEהפתרון לזה הוא יצירת עותק של טבלת הנתונים בצורה מפורשת ע”י שימוש בפקודת
()copy
DT <- data.table(x=rnorm(10,mean=0,sd=1), y=seq(1,10), z=sample(letters,10,replace = TRUE))
dt<-copy(DT)
dt[x<3,k:=TRUE]
head(dt)## x y z k
## 1: 0.51156666 1 l TRUE
## 2: -0.06283975 2 f TRUE
## 3: -0.84018971 3 g TRUE
## 4: -1.14976740 4 a TRUE
## 5: 1.16263251 5 h TRUE
## 6: 0.04766677 6 e TRUEhead(DT)## x y z
## 1: 0.51156666 1 l
## 2: -0.06283975 2 f
## 3: -0.84018971 3 g
## 4: -1.14976740 4 a
## 5: 1.16263251 5 h
## 6: 0.04766677 6 e4.2.5 להפוך דאטה רוחבי לאורכי
אני משתמש בפקודת
melt
של חבילת
data.table
שמהווה הרחבה לפקודה מחבילת
reshape2
ההצעה שמופיעה בקובץ העזרה של
melt.data.table?
היא לא לטעון את חבילת
reshape2
אבל אם מאיזושהי סיבה טוענים את reshape2
אז לטעון אותה לפני טעינת
data.table.

תרשים 4.1: מקור: rdatatable cheatsheet
dt<-data.table(name=c("Donald","Barack","George"),
age=rnorm(3,70),
hight=rnorm(3,190),
wight=runif(3,80,90),
z=seq(1:3))
dt## name age hight wight z
## 1: Donald 69.52247 191.3344 87.15670 1
## 2: Barack 69.18604 189.7778 85.54083 2
## 3: George 69.35258 189.9679 89.90060 3melt.dt<-melt(data =dt,id.vars = c("name"),measure.vars = c("age","hight","wight"))
melt.dt## name variable value
## 1: Donald age 69.52247
## 2: Barack age 69.18604
## 3: George age 69.35258
## 4: Donald hight 191.33445
## 5: Barack hight 189.77779
## 6: George hight 189.96792
## 7: Donald wight 87.15670
## 8: Barack wight 85.54083
## 9: George wight 89.90060שורה בדאטה כוללת 4 מאפיינים לכל אדם, גיל משקל גובה ומשתנה נוסף Z לאחר שנשנה את הדאטה נביא אותו למצב שבשורה יש רק מאפיין אחד לכל אדם כך ששורה אחת בדאטה הפכה לשלוש, וכל שם יופיע בשלוש שורות.
יש לשים לב שמשתנים שלא נכנסו תחת אף אחת מהקטגוריות לא יהיו בדאטה החדש.
- כל המשתנים שנכניס ל
measure.varsיהפכו להיות חלק מעמודה אחת id.varsמציין את המשתנה המזהה , במקרה שלנו השם.
נשתמש בפקודה זו לא אחת לפני שנרצה לבצע גרפים ע”י
ggplot
4.2.6 להפוך דאטה אורכי לרוחבי
זוהי למעשה פעולה הפוכה לפעולה הקודמת.
גם את פעולה זו אבצע באמצעות פקודת
dcast
מחבילת
data.table

תרשים 4.2: מקור: rdatatable cheatsheet
ארצה להגיע חזרה לדאטה ממנו התחלתי
dcast(data =melt.dt, name~variable,value.var = "value")## name age hight wight
## 1: Barack 69.18604 189.7778 85.54083
## 2: Donald 69.52247 191.3344 87.15670
## 3: George 69.35258 189.9679 89.90060ניתן להגדיר את המזהה של השורה ע”י שני משתנים, מבצעים זאת באמצעות סימן חיבור באגף שמאל של המשוואה.
4.2.7 מיזוג
בדאטה טייבל ובSQL נקרא גם join מיזוג בין שני מסדי נתונים תוך שימוש בעמודה אחת או מספר עמודות שלפיהן מתאימים בין השורות בכל מסד נתונים. נשים לב שמסדי הנתונים יכולים להיות שונים באורכם, במספר העמודות שלהם או בסדר בו הנתונים ומופיעים ובלבד שיש עמודה/עמודות זהות שלפיהן ניתן ל”צמד” בין מסדי הנתונים.
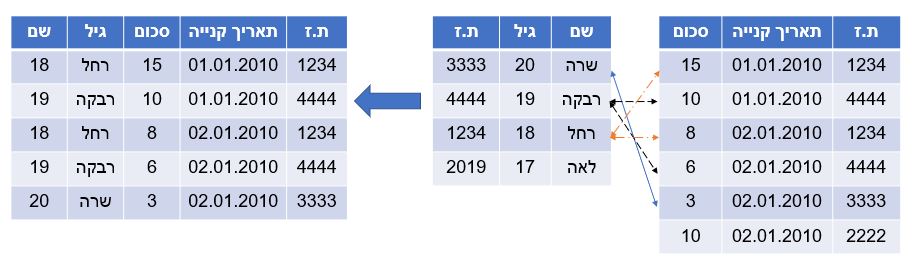
תרשים 4.3: Inner Join
ניצור שני בסיסי נתונים שנרצה לשלב ביניהם
pop.dt<-data.table(Country=rep(c("Israel","UK","USA"),4),
Year=rep(c(2015:2018),each=3),
population=round(rnorm(12,1000,50)))
gdp.dt<-data.table(Country=rep(c("Israel","UK","USA"),4),
Year=rep(c(2015:2018),each=3),
gdp=round(rnorm(12,30000,50)))
#Remove some of the rows
set.seed(1)
pop.dt<-pop.dt[sample(1:12,9,replace = FALSE),]
gdp.dt<-gdp.dt[sample(1:12,9,replace = FALSE),]
pop.dt## Country Year population
## 1: USA 2017 912
## 2: Israel 2016 982
## 3: Israel 2017 984
## 4: Israel 2015 986
## 5: UK 2015 927
## 6: UK 2016 1063
## 7: USA 2015 1088
## 8: UK 2017 968
## 9: USA 2016 911gdp.dt## Country Year gdp
## 1: USA 2015 29908
## 2: Israel 2015 30061
## 3: UK 2016 29992
## 4: Israel 2018 29946
## 5: UK 2015 29984
## 6: USA 2016 29957
## 7: Israel 2017 29970
## 8: UK 2017 30083
## 9: USA 2018 29969נרצה לחשב תלג לאדם gdp_per_capita
בשביל לעשות את זה אנחנו צריכים דאטה שיש בו גם את התל”ג וגם את השנה.
נמזג בין מסדי הנתונים על סמך האינטרקציה של שנה*מדינה
merged.dt<-merge(x = pop.dt,y = gdp.dt,by =c("Year","Country") , all = FALSE)
merged.dt## Year Country population gdp
## 1: 2015 Israel 986 30061
## 2: 2015 UK 927 29984
## 3: 2015 USA 1088 29908
## 4: 2016 UK 1063 29992
## 5: 2016 USA 911 29957
## 6: 2017 Israel 984 29970
## 7: 2017 UK 968 30083כעת נוכל ליצור משתנה חדש באמצעות
merged.dt$gdp_pc<merged.dt$gdp/merged.dt$population## logical(0)נשים לב שהדאטה כאן מכיל רק שורות שנמצאו בשני מסדי הנתונים, פעולה זו נקראת גםinner join
לחילופין, ניתן לבצע left/right outer join שבה אנחנו שומרים גם תצפיות שלא מצאו התאמה בדאטה השני.
דוגמה לleft outer join
merged.dt<-merge(x = pop.dt,y = gdp.dt,by =c("Year","Country") , all.x = TRUE, all.y = FALSE)
merged.dt## Year Country population gdp
## 1: 2015 Israel 986 30061
## 2: 2015 UK 927 29984
## 3: 2015 USA 1088 29908
## 4: 2016 Israel 982 NA
## 5: 2016 UK 1063 29992
## 6: 2016 USA 911 29957
## 7: 2017 Israel 984 29970
## 8: 2017 UK 968 30083
## 9: 2017 USA 912 NAאנחנו לוקחים את הדאטה השמאלי “ומצמידים” לו תצפיות מתאימות מהדאטה הימני כאשר הן קיימות.
אפשרת להסתכל על זה גם דרך דיאגרמות וון:
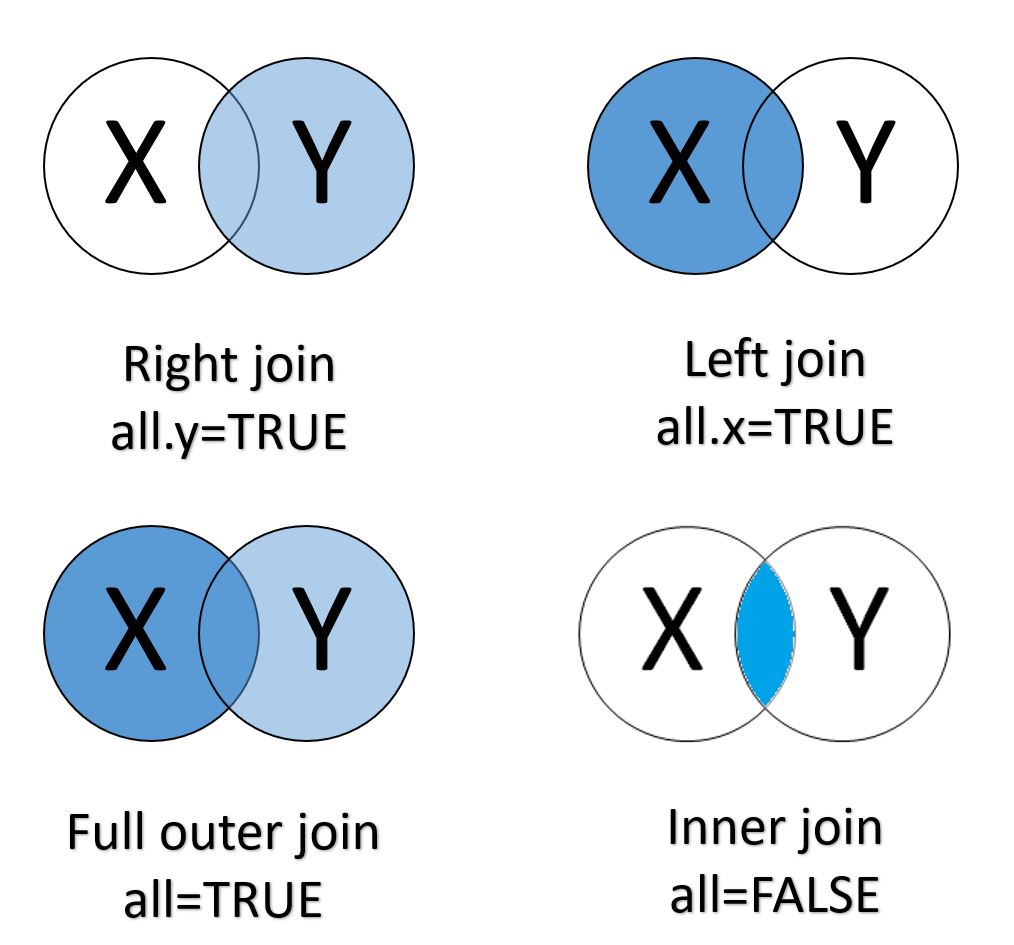
תרשים 4.4: Join types
4.3 להוסיף
data.table- setky
rbind